Evolving the input queue
AFL은 새로운 상태 전환을 유도한 변형 테스트 케이스를 입력 큐에 추가하고, 이를 미래 퍼징 라운드의 시작점으로 활용한다. 이 테스트 케이스는 기존에 발견된 것들을 보완하지만, 자동으로 대체하지는 않는다.
AFL의 이러한 접근 방식은 더 탐욕적인 유전 알고리즘과는 달리, 도구가 다양한 비연관적이고 상호 배타적인 특성을 점진적으로 탐색할 수 있게 해 준다. 이는 다음과 같은 방식으로 진행된다.
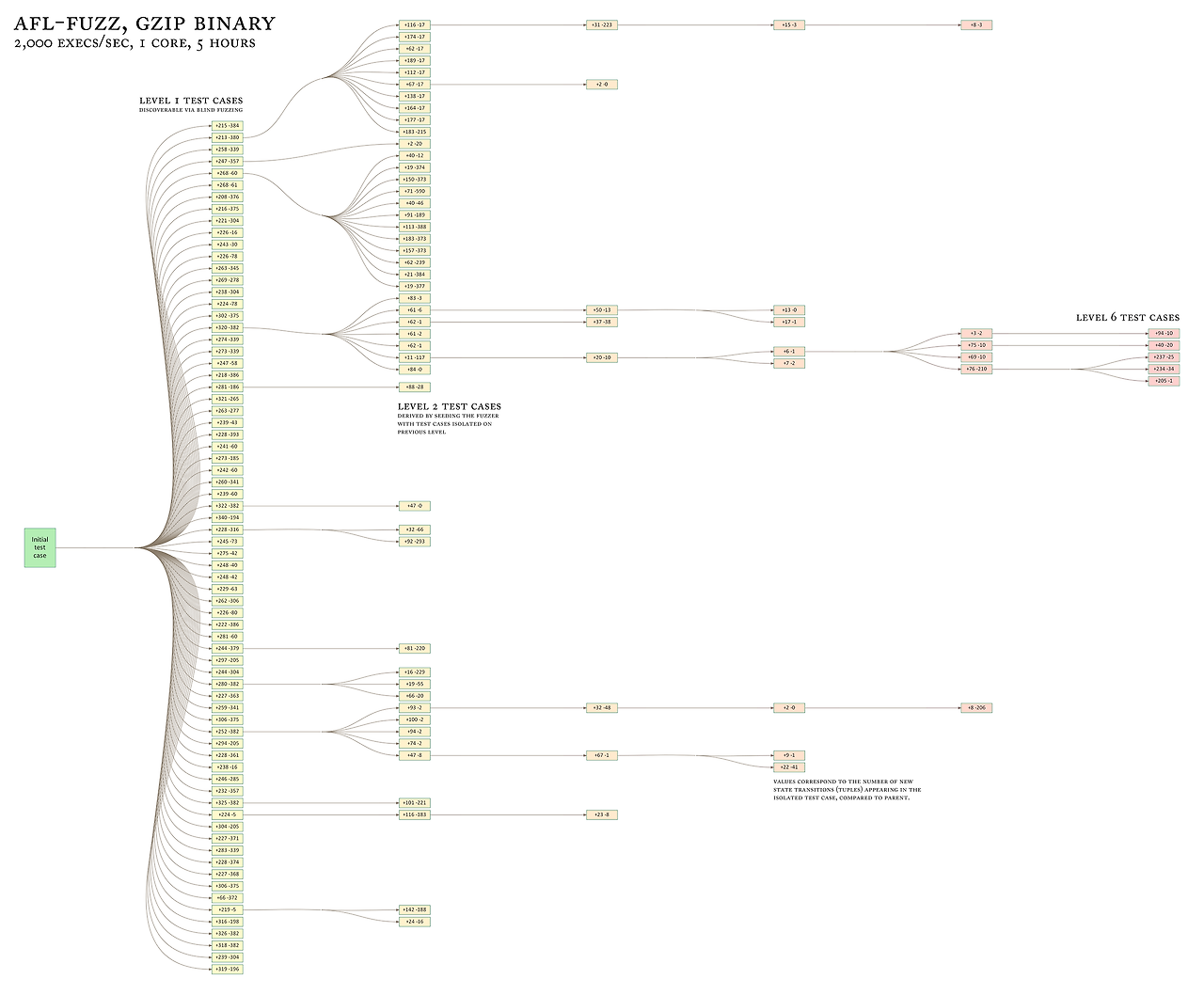
이 과정에서 생성되는 합성 코퍼스(synthetic corpus)는 "이 입력은 새로운 작업을 수행한다!"는 인사이트를 제공하는 입력 파일의 집합으로, 향후 다른 테스트 프로세스의 시드(seed)로 사용할 수 있다. 예를 들어, 리소스 집약적인 데스크톱 앱을 수동으로 stress-test하는 데 활용될 수 있다.
코퍼스는 퍼징에서 사용하는 입력 데이터 집합을 의미한다.
입력 큐 성장과 새로운 튜플
AFL의 입력 큐는 대부분의 타겟에서 1,000개에서 10,000개 항목으로 성장하며, 이 중 약 10~30%는 새로운 튜플의 발견에 기인하고, 나머지는 히트 카운트의 변화와 관련이 있다.
퍼저 전략 비교
다양한 유도 퍼징 전략을 사용할 때 파일 구문을 발견하고 프로그램 상태를 탐색하는 상대적인 능력을 비교한 표는 다음과 같다. 이 실험은 GNU patch 2.7.3을 -O3로 컴파일하고 더미 텍스트 파일로 시드 한 후, 입력 큐에 대해 단일 패스를 수행한 결과이다.
| 퍼저 유도 전략 | 도달한 블록 수 | 도달한 엣지 수 | 엣지 히트 카운트 변화 | 생성된 최대 커버리지 테스트 케이스 |
| 초기 파일 | 156 | 163 | 1.00 | (없음) |
| 블라인드 퍼징 S | 182 | 205 | 2.23 | RCS diff의 첫 2 B |
| 블라인드 퍼징 L | 228 | 265 | 2.23 | -c 모드 diff의 첫 4 B |
| 블록 커버리지 | 855 | 1,130 | 1.57 | 거의 유효한 RCS diff |
| 엣지 커버리지 | 1,452 | 2,070 | 2.18 | 한 덩어리 -c 모드 diff |
| AFL 모델 | 1,765 | 2,597 | 4.99 | 네 덩어리 -c 모드 diff |
첫 번째 블라인드 퍼징 전략(S)는 단일 테스트 라운드를 실행한 결과를 나타내며, 두 번째 전략(L)은 계측된 실행과 유사한 수의 실행 사이클을 반복하여 수행한 결과이다.
다른 큐 확장 전략
별도의 실험에서는 퍼저를 수정하여 모든 랜덤 퍼징 단계를 제거하고, 비트 플립과 같은 일련의 기본적인 순차 작업만 남겼다. 이 모드에서는 입력 파일의 크기를 변경할 수 없으므로 유효한 통합 diff로 세션을 시도했다.
| 큐 확장 전략 | 도달한 블록 수 | 도달한 엣지 수 | 엣지 히트 카운트 변화 | 발견된 고유 충돌 수 |
| 초기 파일 | 624 | 717 | 1.00 | |
| 블라인드 퍼징 | 1,101 | 1,409 | 1.60 | 0 |
| 블록 커버리지 | 1,255 | 1,649 | 1.48 | 0 |
| 엣지 커버리지 | 1,259 | 1,734 | 1.72 | 0 |
| AFL 모델 | 1,452 | 2,040 | 3.16 | 1 |
이전에 언급한 바와 같이, 유전 퍼징에 대한 일부 연구는 단일 테스트 케이스를 유지하고 이를 진화시켜 커버리지를 극대화하는 데 의존했다. 그러나 위에서 설명한 테스트에서는 이러한 탐욕적인 접근 방식이 블라인드 퍼징 전략에 비해 이점을 제공하지 않는 것으로 나타났다.
Culling the corpus
AFL의 상태 탐색 과정은 테스트 케이스가 진화하면서, 나중에 생성된 테스트 케이스가 그 이전 테스트의 엣지 커버리지를 초과하는 경우가 발생할 수 있다. 이를 해결하기 위해 AFL은 주기적으로 큐를 재평가하고, 빠른 알고리즘을 사용하여 여전히 모든 튜플을 커버하는 더 작은 테스트 케이스 집합을 선택한다. 이 과정은 퍼징의 효율성을 최적화하기 위한 것이다.
알고리즘의 동작 원리
이 알고리즘은 각 큐 항목에 실행 지연 시간과 파일 크기에 비례하는 점수를 할당한다. 그 후, 각 튜플에 대해 가장 낮은 점수를 가진 항목을 선택하는 방식으로 작동한다. 튜플 처리 순서는 다음과 같은 간단한 흐름으로 진행된다.
- 임시 작업 세트에 포함되지 않은 다음 튜플을 찾는다.
- 해당 튜플에 대한 최적의 큐 항목을 찾는다.
- 그 항목의 실행 경로에 포함된 모든 튜플을 작업 세트에 등록한다.
- 모든 튜플이 작업 세트에 포함될 때까지 1단계로 돌아간다.
이렇게 생성된 우선 항목 집합은 원래 데이터 세트보다 보통 5~10배 작아진다. 우선 항목으로 선택되지 않은 항목은 삭제되지 않지만, 큐에서 우선 항목을 처리하는 동안 일정 확률로 건너뛰게 된다.
스킵 확률
- 새로운 우선 순위 항목이 큐에 있을 경우: 우선 항목이 아닌 항목은 99%의 확률로 건너뛰어 우선 항목에 도달한다.
- 새로운 우선 항목이 없을 경우
- 이미 퍼징된 우선 항목이 아닌 항목은 95%의 확률로 스킵된다.
- 아직 퍼징되지 않은 항목은 75%의 확률로 스킵된다.
이 접근 방식은 큐 순환 속도와 테스트 케이스의 다양성 간의 균형을 제공하여 퍼징의 성능을 높인다.
더 정교한 접근: afl-cmin
AFL은 더 정교하지만 느린 방법으로 입력 또는 출력 코퍼스를 정리할 수 있다. afl-cmin 도구를 사용하면 중복된 항목을 영구적으로 제거하고, 더 작은 코퍼스를 생성할 수 있다. 이 코퍼스는 afl-fuzz 또는 다른 외부 도구에서 사용할 수 있다.
Trimming input files
파일 크기는 퍼징 성능에 큰 영향을 미친다. 큰 파일은 타겟 바이너리의 실행 속도를 늦추고, 변이가 중요한 형식 제어 구조를 건드릴 확률을 줄인다. 또한 사용자가 낮은 품질의 코퍼스를 제공할 가능성이나, 변이 과정에서 파일 크기가 증가하는 경우도 있기 때문에, 입력 파일 크기를 제어하는 것이 중요하다.
다행히도, AFL은 계측 피드백을 사용하여 입력 파일을 자동으로 줄일 수 있다. 이 과정에서 파일 크기 감소가 실행 경로에 영향을 미치는 경우에만 변경을 적용한다.
afl-fuzz 내장 트리머
AFL 퍼저인 afl-fuzz는 내장된 트리머를 통해 입력 파일을 트리밍한다. 이 트리머는 다양한 크기와 스탭오버를 가진 데이터 블록을 제거하려고 시도하며, 트레이스 맵의 체크섬에 영향을 주지 않는 삭제는 디스크에 저장된다. 내장 트리머는 매우 정밀하지는 않지만, 파일당 평균 5~20%의 크기 감소를 목표로 하며 성능과 정확성의 균형을 유지한다.
afl-tmin: 독립형 파일 최소화 도구
더 정밀한 최소화를 위해 afl-tmin이라는 독립형 도구가 사용된다. afl-tmin은 보다 철저한 알고리즘을 사용하여 파일 크기를 줄이고, 알파벳 정규화 작업을 통해 불필요한 문자를 제거한다. 이 도구는 타겟 바이너리의 상태에 따라 두 가지 모드를 선택한다.
- 크래시 발생 시: 비계측 모드에서, 크래시를 발생시키는 더 작은 파일을 유지한다.
- 크래시 미발생 시: 계측 모드에서, 동일한 실행 경로를 생성하는 데 더 작은 파일을 유지한다.
계측 모드와 비계측 모드는 퍼징 도구에서 입력 파일을 처리할 때 사용하는 두 가지 주요 방식이다.
계측 모드 (Instrumented Mode): 타겟 프로그램에 코드가 삽입되어 프로그램의 실행 경로를 추적하는 방식
비계측 모드 (Non-instrumented Mode): 프로그램에 별도의 계측 코드를 삽입하지 않고, 단순히 프로그램의 크래시 여부만을 확인하는 방식
afl-tmin의 최소화 알고리즘
- 큰 블록의 데이터 제거: 큰 스탭오버와 블록 크기를 사용하여 데이터를 0으로 채우는 방식이다. 이는 나중에 세밀한 작업을 줄이고, 실행 횟수를 줄이는 데 효과적이다.
- 이진 검색 스타일 삭제: 점진적으로 블록 크기와 스탭오버를 줄이며, 블록을 삭제한다.
- 알파벳 정규화: 파일 내에서 사용되는 고유 문자를 계산한 후, 해당 문자들을 0x00으로 교체하는 작업이다.
- 바이트 단위 정규화: 마지막으로, 비제로 바이트에 대해 한 바이트씩 정규화를 수행한다.
스탭오버 (Step-over): 퍼징 과정에서 입력 파일을 변형하거나 최소화할 때 블록을 제거하는 간격 또는 바이트를 처리하는 간격을 의미한다.
afl-tmin은 일반적인 0x00 대신 ASCII '0'을 사용해 파일을 트리밍 하는데, 이는 텍스트 파일의 파싱을 방해하지 않기 위해서이다. 이 방식은 실행 횟수가 적으면서도 실용적인 결과를 만들어낸다.
Fuzzing strategies
AFL은 다양한 파일 형식에서 퍼징 효율을 극대화하기 위해 계측 피드백을 활용하여 퍼징 전략을 최소화한다. 이 전략들은 파일 형식에 구애받지 않고 동작하며, AFL이 사용하는 퍼징 전략은 크게 결정적(deterministic)과 비결정적(non-deterministic) 전략으로 나눌 수 있다.
결정적 퍼징(Deterministic Fuzzing)
결정적 퍼징은 퍼징 초기 단계에서 수행되며, 순차적으로 입력 데이터를 변형하는 방법이다. 이 단계는 실행 경로에 미치는 영향을 세밀하게 분석하여 크래시와 비크래시 입력 간의 작은 차이를 유발하는 테스트 케이스를 만들어내는 데 중점을 둔다. 주요 크래시 전략으로는 다음이 있다.
- 비트 플립(Bit Flips): 데이터를 1비트씩 순차적으로 변경하거나, 여러 비트를 동시에 플립하는 방식
- 정수 더하기/빼기: 파일의 일부를 작은 정수 값을 더하거나 빼면서 변형
- 흥미로운 값 대입: 예를 들어 0, 1, INT_MAX 같은 중요한 정수를 파일에 삽입
이러한 결정적 단계는 실행 경로의 변화에 대한 피드백을 즉각적으로 얻을 수 있으며, 특히 크기가 작고 간결한 테스트 케이스를 만들어 내는 데 효과적이다.
비결정적 퍼징(Non-deterministic Fuzzing)
결정적 퍼징 단계과 완료된 후, AFL은 비결정적 전략을 적용한다. 비결정적 퍼징은 무작위로 파일을 변형하며, 결정적 단계에서 발견되지 못한 상태 전이를 탐지하는 데 중점을 둔다. 비결정적 퍼징 전략으로는 다음이 있다.
- 랜덤 비트 플립: 무작위로 선택한 비트들을 플립
- 삽입/삭제: 파일에 임의의 데이터를 삽입하거나 삭제
- 산술 연산: 임의로 선택한 파일의 부분에 산술 연산을 적용
- 테스트 케이스 스플라이싱(Test Case Splicing): 두 개 이상의 테스트 케이스를 섞어서 새로운 입력을 생성
비결정적 단계에서는 결정적 전략이 미처 탐지하지 못한 다양한 코드 경로를 추가로 탐색하며, 퍼징의 범위를 확장한다.
효과 맵(Effector Maps)
퍼징 과정에서 일부 파일의 특정 부분이 프로그램 실행 경로에 아무런 영향을 미치지 않는 경우, AFL은 이를 감지하여 남은 결정적 단계에서 그 부분을 건너뛰도록 설정한다. 이를 통해 불필요한 변형을 줄여 실행 속도를 최대 10~40%까지 높일 수 있으며, 특정 데이터 형식에서는 최대 90%까지 성능 향상이 가능하다.
'Fuzzing > AFL++' 카테고리의 다른 글
| AFL++ 동작 원리 - 3 (3) | 2024.10.03 |
|---|---|
| AFL++ 동작 원리 - 1 (0) | 2024.10.02 |