1. 디지털 증거의 특성
디지털 포렌식의 대상은 디지털 증거(Digital Evidence)이며 전자증거(Electronic Evidence)로도 불린다. 일반적으로 디지털 증거가 기존의 물리적 증거와 구별되는 특성은 매체독립성, 비가시•비가독성, 취약성, 대량성, 네트워크 관련성 등이 주로 거론된다. 이러한 각각의 특성을 정리해 보면 아래와 같다.
| 특징 | 내용 |
| 비가시성(Latent) | 사람의 시각으로 바로 식별이 불가하고 변환장치나 판독장치를 이용하여야 판독 가능함. 내부데이터만으로 내용을 바로 확인하기 어려우며 디코딩(Decoding), 복호화(Decrypt), 압축 해제(Decompress) 등의 과정이 필요하며 여러 정보가 누락되고 최종적으로 가시적인 정보만 제공될 수 있다. |
| 취약성(Fragile) | 삭제, 변경 등이 용이하여 위변조하기 쉬워 무결성의 문제가 대두된다. |
| 대용량성(Massive) | 최근 저장기술의 발전으로 저장매체의 크기가 커져 하나의 방대한 데이터가 저장되어있어 수작업으로 필요한 정보를 찾기는 어렵게 되었다. |
| 네트워크성(Network) | 현재의 정보기기는 고립되어 있지 않고 각종 네트워크에 서로 연결되어 있다. 그러므로 증거 자료 및 행위가 국경을 넘는 경우가 많아 사법 처리에 한계가 있기도 하며 해킹을 당하기도 쉬워 국제적인 사법공조가 필요하기도 하다. |
| 매체독립성(Media dependence) | 디지털 증거는 유체물이 아니고 각종 디지털 저장매체에 저장되어 있거나 네트워크를 통하여 전송 중인 정보 그 자체를 말한다. 이 정보는 0과 1로만 구성되는 2진수로 변환하여 저장되기 때문에 저장된 정보의 값이 같다면 어느 매체에 저장되어 있든지 동일한 가치를 지닌다. |
2. 디지털 증거 처리 기본원칙
디지털 증거의 특성을 살펴보면 위변조가 매우 쉽다는 특징을 가지고 있으므로 수집된 증거가 증거효력을 가지기 위해서는 준수되어야만 하는 여러 기본원칙이 있다.
첫 번째, 무결성의 원칙으로 디지털 증거의 내용은 변경되지 않아야 한다는 원칙이다. 증거물 수집 및 분석 절차에서 발생 가능한 변경을 방지하고 무결성을 증명하는 조치가 수행되어야 한다는 것이다.
두 번째, 재현의 원칙으로 분석관이 여러 가지 다양한 증거 분석도구를 사용하기 때문에 다른 분석관이 다른 프로그램을 사용하게 되더라도 동일한 시스템을 분석하였을 경우 동일한 결과가 나와야 한다는 원칙이다. 즉, 신뢰성이 보장된 분석 프로그램과 장비를 사용하여 분석 결과의 신뢰성을 확보해야 함을 뜻한다.
세 번째, 보관의 연속성 원칙으로 증거물 수집, 이송, 보관, 법정 제출 단계에서 담당자, 책임자, 입회자를 명확히 기록하고 증거 분석 시 모든 과정을 상세히 기록하는 문서화 작업을 하여 추후 사후 검증 요구 시 신뢰성을 명확히 확보하는 것이다.
그 외의 다른 법칙으로는 정당성, 신속성의 원칙을 두기도 한다.
정당성의 원칙
증거를 획득할 때는 적법절차를 통하여 얻어야 한다는 원칙이다. 정당성의 원칙은 적법절차의 원칙이라고도 한다.
신속성의 원칙
디지털 포렌식 수행의 과정은 불필요한 지체 없이 신속하게 진행되어야 한다는 원칙이다. 전자정보 특성상 삭제가 쉽고, 휘발성 데이터는 시간이 지나면 소멸되기 때문에 신속한 대응 여부에 따라 디지털 증거의 획득 여부가 결정되기 때문에 신속하게 처리되어야 한다.
3. 이미징
위에서 살펴보듯이 디지털 증거 획득 시 증거 능력이 훼손되지 않게 무결성을 보장하여 증거를 획득하는 것이 디지털 포렌식에서 가장 중요한 부분이라고 할 수도 있다.
기술적으로 이를 수행하기 위해서 실무에서는 쓰기 방지 장치를 이용하여 저장매체 복제나 이미징을 통하여 무결성을 가진 증거를 획득하고 사후 검증을 위해 해시값과 문서화를 통해 이를 검증한다.
컴퓨터에 USB를 연결하여 파일을 보기만 하여도 운영체제가 여러 가지 내용을 쓰기 때문에 무결성이 훼손된다. 이러한 쓰기를 못하게 하기 위해서는 쓰기 방지 장치 하드웨어를 사용하거나 Encase 프로그램을 사용하는 경우에는 FastBloc 기능을 동작시켜야 한다. 윈도를 사용하는 경우에는 레지스트리에 쓰기 방지 설정을 하여도 된다.
저장매체 하드디스크나 USB를 같은 내용을 가진 다른 매체를 만들려고 하는 경우, 복사, 복제, 이미징을 통해 할 수 있다.
복사는 파일 또는 디렉터리를 마우스로 드래그 앤 드롭을 통해 복사하거나 윈도 명령어 copy나 xcopy를 통해 내용을 복사할 수 있다. 이 방법은 파일을 내용만 복사하기 때문에 삭제된 데이터를 복구할 수 없다.
복제는 원본 내 물리적인 섹터를 내용 그대로 사본 물리 섹터로 똑같이 복사하는 방식이다. 원본과 똑같이 복사되기 때문에 슬랙 공간 및 지워진 데이터 또한 그대로 복사가 되어 삭제된 데이터를 복구할 수 있다. 물리적 섹터가 모두 동일하게 복사되기 때문에 원본매체와 동일한 모델 및 사양의 저장매체를 사용하는 경우가 아닌 경우에는 사본은 원본보다 커야 한다.
이미징은 원본 내 모든 물리적 데이터의 1번 섹터에서 마지막 섹터까지 모든 데이터가 파일 형태로 저장된다. 복제와 마찬가지로 슬랙 공간과 비할당 영역까지 저장되어 삭제된 데이터를 복구할 수 있다.
원본과 내용이 동일한 dd 명령어로 이미징 하거나 데이터를 압축하여 크기를 줄이거나 암호화를 통해 데이터를 보호할 수 있는 *. E01과 같은 포렌식 이미지 포맷을 사용하기도 한다. 그리고 이미징은 파일 형태이기 때문에 배포 및 검증이 쉬운 장점이 있다.
4. 포렌식 파일 포맷
RAW
dd(disk dump) 명령어로 생성 가능하며 확장자로 001을 사용한다. dd는 디스크 내 각각의 모든 섹터를 완전히 동일하게 바이트 단위 전송으로 동일한 raw 레벨 복사본을 만들기 때문에 원본과 완전히 동일한 형태의 이미지 파일이 생성된다.
Raw는 직관적으로 바로 분석이 가능하다는 장점이 있지만, 오류 처리 및 해시 함수와 같은 무결성 보장 기능이 없다는 단점이 존재한다.
EWF(Expert Witness Compression Format)
포렌식 전용 제품의 포렌식 이미지 포맷은 raw 이미지와 달리 생성일, 생성자, 매체세부 정보, 해시 등 메타데이터를 포함하며 압축 기능 및 암호화 기능을 제공하며 신뢰성 및 편의성이 높아 많이 사용한다.
대표적인 포렌식 툴인 EnCase도 전문 증거 압축 포맷을 제공하고 해시, 압축, 암호화 기능 등을 제공한다. EnCase v6까지 E01 형식을 사용하며 EnCase v7부터는 Ex01 형식도 제공한다.
E01 파일은 3가지 기본 요소(헤더, 체크섬, 데이터 블록)로 구성되어 있으며, 헤더는 증거 파일 생성 시 조사관이 입력한 관리 정보, 세그먼트 수와 크기 등이 포함되며 체크섬(CRC)은 아래 그림에서 보듯이 각 데이터 블록 뒤에 첨부되어 데이터의 오류를 감지한다. 마지막에는 MD5 등 해시가 들어있으며 그 외에 압축 및 암호화 기능이 가능하다.

데이터 블록은 보통 64 섹터로 구성되어 있으며 데이터 블록의 CRC를 계산하고 끝 부분에 CRC 값을 비교하여 데이터의 오류를 검사하며 MD5 해시는 데이터 블록들 값으로만 계산하여 마지막 해시 데이터와 비교하여 무결성을 검사한다.
v7에서는 이전 버전에서 사용한 E01이 아닌 Ex01의 확장자를 가진 새로운 포맷을 제공한다. 이 형식은 여전히 32 비트 CRC로 데이터를 검증하고 있으며, bzip 압축을 통해 압축 성능을 높였다. 그리고 증거 파일의 무결성을 보장하기 위해 MD5, SHA1 해시를 사용할 수 있고 증거 파일을 암호화하기 위해 AES256을 사용하는 등 암호화 성능을 높였다.
E01 포맷은 EnCase뿐 아니라 FTK Imager, X-ways, Forensice 소프트웨어에도 공통으로 제공하는 형식이다.
5. 해시 함수
디지털 포렌식에서 원본의 무결성을 보이기 위하여 해시 함수를 사용한다. 해시 함수는 가변 길이의 입력 데이터를 받아 일정한 길이의 출력 데이터로 변환시켜 주는 함수이다. 해시 함수는 원래의 값을 변환한 출력 키로 이용되어 검색하는 데 사용될 수 있으며 파일의 무결성을 검증하는 데 사용된다. 디지털 포렌식에서는 주로 MD5와 SHA-1을 사용한다.
MD5
Message-Digest algorithm 5의 약자로 임의의 입력 데이터를 128비트, 즉 32개의 16진수 값 고정 길이의 출력 값으로 변환한다.
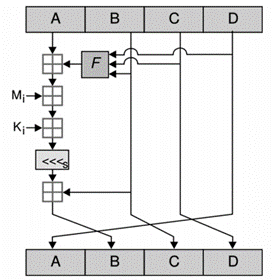
MD5는 가변길이 입력 메시지를 512비트 블록(16개의 32비트 단어)의 청크로 나눈다. 메시지는 길이가 512로 나누어지도록 패딩 된다. 패딩은 다음과 같이 작동한다. 먼저 단일 비트 1이 메시지 끝에 추가된다. 그다음에는 메시지 길이를 512의 배수보다 작은 64비트로 만드는 데 필요한 만큼의 0이 온다. 나머지 비트는 원본 메시지의 길이를 나타내는 64비트로 채워진다. 이후 MD5 알고리즘은 A, B, C 및 D로 표시된 4개의 32 비트 워드로 분할된 128비트 상태로 만든다. 이들은 특정 고정 상수로 초기화된다. 그런 다음 각 512비트 메시지 블록을 차례로 사용하여 상태를 수정한다. 메시지 블록의 처리는 라운드라고 하는 4개의 유사한 단계로 구성된다. 각 라운드는 비선형 함수 F, 모듈식 덧셈 및 왼쪽 회전을 기반으로 하는 16개의 유사한 연산으로 구성된다. 아래 그림은 라운드 내 하나의 작업을 보여준다.
SHA1
SHA-1은 Secure Hash Algorithm의 약자로 미국 정부의 Capstone 프로젝트의 일부로 개발되었다. MD5와 유사한 원리에 기초하여 변환하지만 128비트 고정 길이가 아닌 160비트, 즉 40개의 16진수로 변환된다.
SHA-1은 TLS 및 SSL, PGP, SSH, S/MIME 및 IPsec을 포함하여 널리 사용되는 여러 보안 응용프로그램 및 프로토콜의 일부에 사용된다.

Fuzzy
일반적인 해시 함수는 1비트라도 입력 값이 변경되면 해시 출력 값도 변경되며 값들 간에 어떠한 연관성을 찾는 것이 불가능하게 된다. 바이러스 연구에 있어 전통적인 정적 분석과 같이 MD5 및 SHA256을 사용하는 암호화 해시는 2013년에 일반적으로 사용되었으나 맬웨어를 만드는 해커는 탐지를 피하기 위해 맬웨어 방지기술에 대응하는 암호화 및 특정 부분 수정을 통한 다양화 등 여러 탐지 방지 기술을 사용한다. 따라서 안티바이러스 분석가는 매일 새로운 악성코드 유형을 파악하고 식별하기 위해 어려움을 겪었다.
동일한 맬웨어 서명을 탐지하기 위한 MD5, SHA-1 및 SHA-256 등 해시 함수는 이런 변형에 곤란을 겪었으나 전체 파일을 고정된 세그먼트로 분리하고 부분 세그먼트에 대한 해시 값, 롤링 해시 값 등을 이용하여 계산하는 새로운 개념의 fuzzy 해시는 이러한 어려움을 극복하여 두 파일 간의 유사성을 판단할 수 있다. 따라서 일정 부분이 유사한 문서를 검색하는 데 있어 효율적인 방법이며 안티바이러스 부분에 널리 사용 중이다.